- システム概要
- 課題点
- メンバー
システム概要
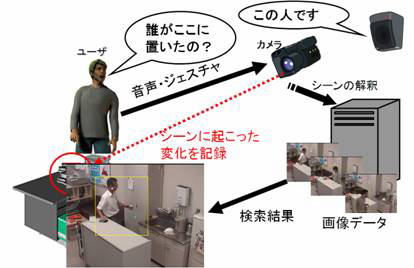
システムの概要は上図のようになっており、主な機能は以下の3つです。
1. イベント検知部
2. イベント解釈部
3. ユーザインタフェース部 以下にそれぞれの機能について説明します。
1. イベント検知部

イベント検知部では室内の様子を撮影した画像列から人が何か物を
- 持ち込んだ
- 持ち去った
- 空間内で移動した
といったシーンを自動的に検知し、保存します。
空間内の変化を検知するために背景画像を作成し、入力画像との差分画像を作成を行います。 背景差分領域で差分が出たところに注目し、物体かどうかを判断します。
物体だと判断された差分はレイヤーとして保存されます。 持ち込み・持ち去りのイベントはこの保存されたレイヤーを使用した複層型背景を用いて検知します。
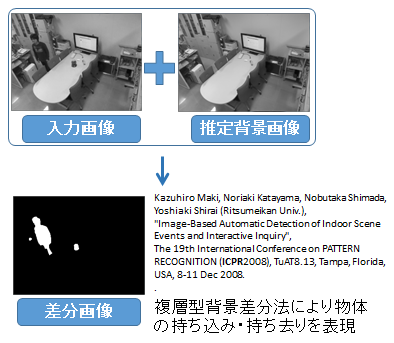
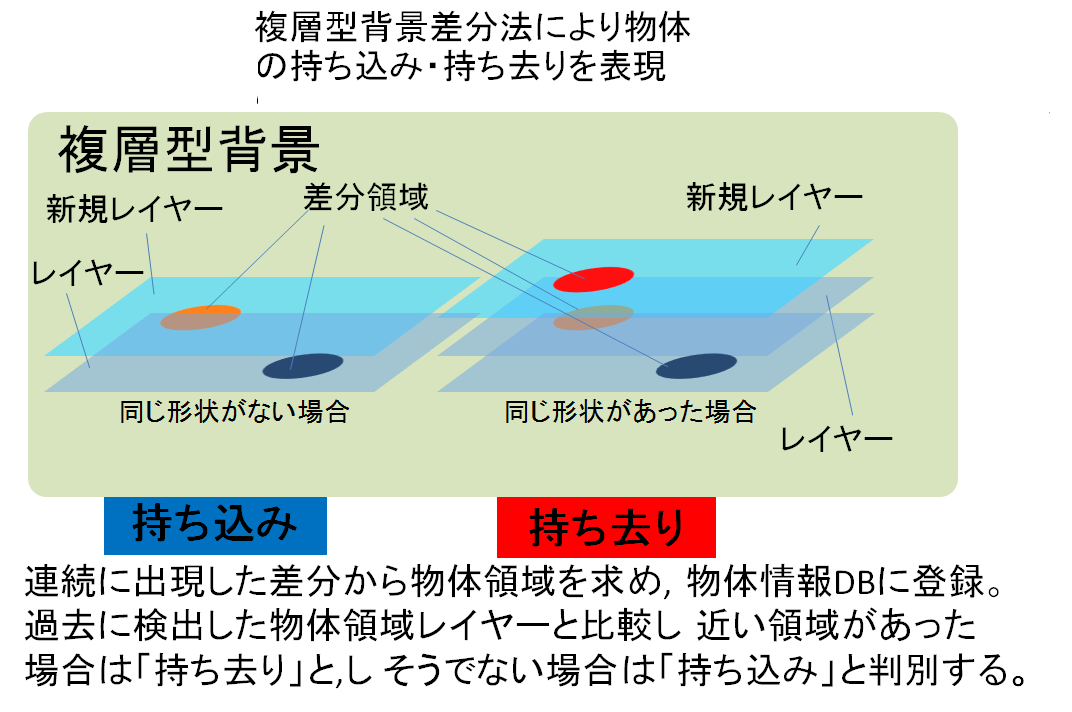
物体検知には、背景差分領域の時系列データを用いています。物体は自ら動くことはないと仮定し、それまでの背景と異なる領域がある一定時間に渡って同じ場所に存在し続けた場合、それを物体領域として抽出します。
現在は、キネクトというセンサを監視カメラとして利用して研究を行っています。
1.1 RGB-Dカメラの距離情報を利用した監視システムの構築

従来のシステムではRGB画像を用いた背景差分法を用いて物体や人物の検知を行っていましたが、背景と対象の色が同じ場合、物体や人物を正確に検出することができず、誤認識するという問題がありました。
そこでRGB-Dカメラから得られる距離情報を用いることで物体や人物が画像内に入った場合、距離の差分が出るためこれを利用することでRGB画像情報では検知されにくかったイベントの検知が可能となりました。
上の動画はセンサーによって得られた距離情報を元に差分を出し物体や人物の検出を行っているシーンである。 一番左端は人物が検出されたらその部分を黄色い枠で表示されるようになっておりその下は背景画像との差分の部分を表示、その下はキネクトから得られた人物のスケルトン情報や検知された物体との接触判定を行っている。 また真ん中の画像は物体候補の領域が表示されており、その下と右の濃淡画像は距離画像が出力されている。
現在のシステムは距離情報を用いることで物体と人物の接触を認識できるようになり、複数人が空間内にいる場合でも物体に対しどの人物がイベントを起こしたのかをシステムが理解することができるようになり、人と物体の関わりを元に検索が可能となりました。
1.2 物体や人物の検知手法

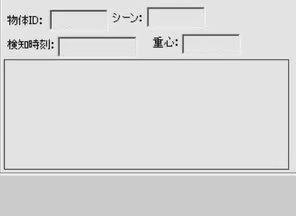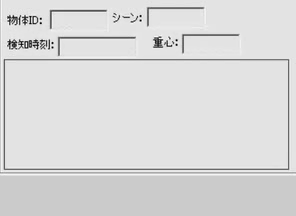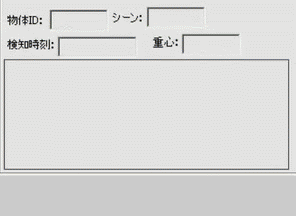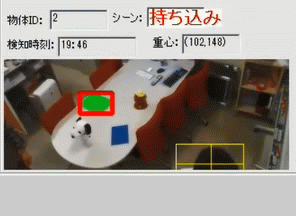
持ち込みイベント検知シーン


持ち去りイベント検知シーン

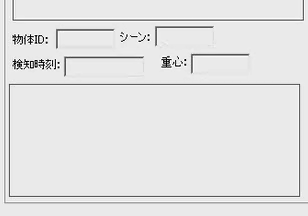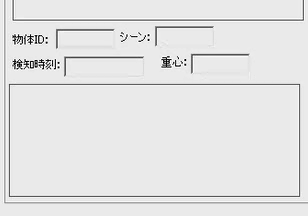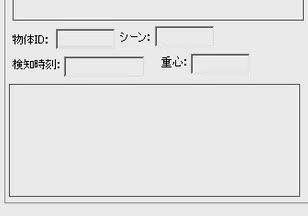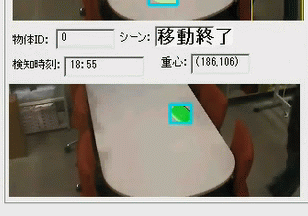
移動イベント検知シーン
現在物体や人物の検知には空間内の距離情報を利用しています。右図の濃淡画像はカメラで撮影している空間の距離情報を画像化したもので、カメラに近いほど明るく、遠くに行くほど暗い色になるように表示しています。現在のシステムはこの距離情報を元に背景の距離画像と現在の深度情報の差分によって検出を行っています。

物体を検知・記録した後はその「物体領域」は背景と同じ扱いとして次フレーム以降に何度もその物体が同じ場所に検知されないように、重なって別の物体が置かれても検知できるようにしています。
2. イベント解釈部 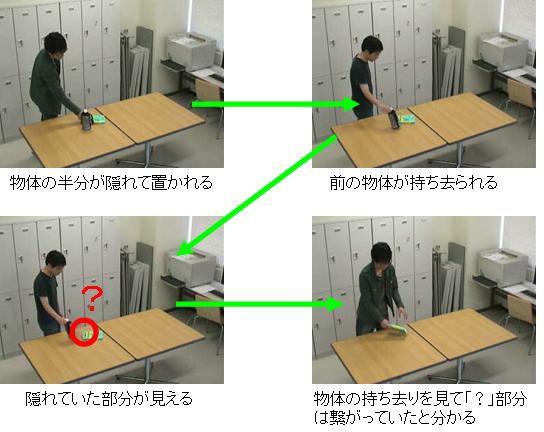
イベント解釈部では、イベント検知部で保存されたシーンについて「いつ?どこで?誰が?何をしたか?」といった情報を付加し、その情報をデータベースに登録・管理します。
現在、監視班では撮影された空間内での人の行動によって物体の情報を得る為の研究を行っています。
例えば、飲む動作をシステムが認識することができれば、飲む動作に関連する物体群をグループ分けすることができそれを元に検索の際臨んだ情報が容易に見つかることが可能となる。 システム内には空間内での物体の移動が検知可能となっており、それ以外の隠す動作や飲む動作など日常で人が行う動作をシステムで認識するための研究を行っています。
2.1 物体のSURFとcamshift追跡を用いた同一物体の認識
従来のシステムでは同一の物体が映像内で移動したとき、イベントとしては物の持ち出し、持ち込み扱いになり、それぞれ違う物体としてシステム内では認識されていました。それを改善するために映像内で移動した物を同一物体として認識するアルゴリズムを研究しました。
まずSURFにより物体の局所特徴量を抽出し、それを元に移動後の物体は同じ物体だと認識するアルゴリズムを導入しました。しかしこれだけの場合、物体の向きや形状が変わった時、特徴量が変化することがあり同一物体と認識されないことがあります。
そこで,映像内の手や物体の動きをCAMSHIFT追跡させるアルゴリズムを導入することで、映像内の物の移動を認識することができるようになりました。これにより、移動により向きや形状が変化した場合でもそれらが同一物体であるとして新たな特徴量を登録し、以後どの向きに置かれた場合でも同じ物体であると認識できるようになりました。
2.2 人と物体の接触検出と領域追跡を用いた物体画像の収集と分類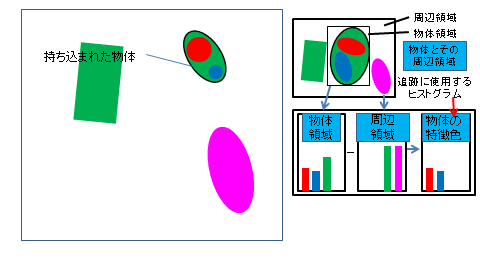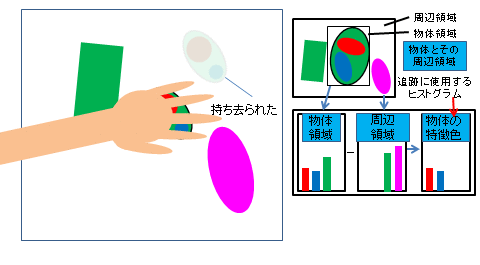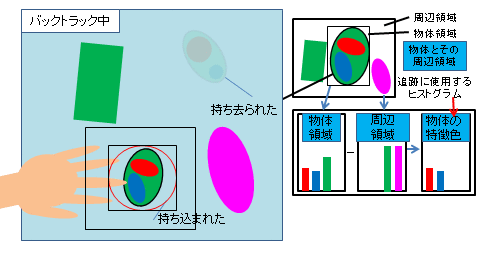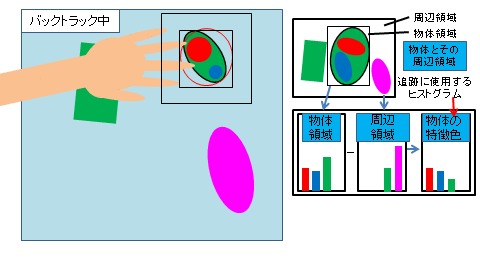
映像内の物の移動を認識するためにCAMSHIFT追跡アルゴリズムを用いていましたが、 物体の移動シーンにも関わらずシステムが「物体が移動した」と認識しないという問題がありました。
従来のシステムは物体の移動イベントが物体の持ち去りイベントを検知した後に物体の持ち込みイベントがあるという前提で判定しているので、 物体の持ち去り時の地点に着目しています。 しかし、システムが瞬時に物体持ち去り検知できないため、持ち去り検知時には物体が置いてあった場所からだいぶ離れている場合があります。 これにより、移動イベントが正常に検知されませんでした。 そこで物体が移動するときは人が関わるという「人と物体の関わり」を見ることで問題解決を行いました。 具体的にはCAMSHIFT追跡によって過去へ遡る終着点を物体の持ち去りが確定した時点ではなく、 物を持ち去る際の人が物体に接触した時点に設定しました。
また、CAMSHIFT追跡を注目したい物体の色のヒストグラムを元に行っていましたが、 これを背景にはなく物体にしかない色のみのヒストグラムを用いるようにしました。 これにより背景に物体と類似する色があっても背景色に引っ張られることがなくなり物体を追跡する性能が向上しました。
2.3 キネクトを利用した特徴的な人物動作の検出
人の動作を認識する手法の1つとしてキネクト内に内蔵されている人物の骨格を検出するシステムを利用する方法がある。監視班では図のように飲む動作の一連の骨格の流れをシステムに記憶させ、以降同じ動作をした際に検知する手法を開発した。 本研究では物体を扱う腕の動作に着目し、動作を行った際の流れの中でも特徴的な部分を抽出し符号化を行います。そしてれと同じ特徴が得られる動作を得た場合はその動作をしたとしてシステムが認識するようになっています。
3. ユーザインタフェース部
ユーザインタフェース部では、ユーザの入力となる指差しなどのジェスチャ認識と音声認識の処理を行い、その問い合わせに応じた結果を提示し対話を行います。
ユーザとの対話を行なうためには、イベント解釈部によって記録された物体検知履歴の情報を用います。物体検知履歴はイベントの起こった時刻や(画像上の)座標からイベントの起きている様子を撮影した画像列を検索できるようなデータベースになっています。このデータベースを用いることで、ユーザの指差しでの座標指定、あるいは発話による時刻指定から、該当するイベントが検索できます。
ユーザの知りたい情報の種別(タスク)の決定には、ユーザの発話に含まれるキーワードを用いました。現在実装しているシステムではタスクとして「誰が持ってきたのか?」「誰が持っていったのか?」の2種類を想定しています。
現在のシステムでは、ユーザの音声発話を切っ掛けとして対話を開始しユーザの指定した座標に関係しているイベントを全て提示してユーザに確認を求めていきます。音声発話を対話開始の切っ掛けとすることでただ通り過ぎるだけの人を対話対象としないようにしています。
従来の屋内シーン検索システムは服装のみで持ち去りまたは持ち込みを行った人物を認識していたため特定の人物を認識するのが困難でした。 現在の検索システムでは,顔認識ライブラリをもとに作成したアルゴリズムを導入することにより、映像内に一度入った人物の顔をデータベース内に入れておき、再び入った時、同一人物であることを認識させることが可能になりました。これによりイベントを起こした特定のユーザを検索することができるようになりました。
従来のインタフェースでは二次元の画像を用いて画像内の肌色をもとに指や顔の場所を認識していたため個人差により事前較正が必要でした。さらに、二次元画像による認識では奥行きが計測できないため指差し場所の特定が難しいという問題がありました。
現在はKinectカメラと部屋内にある監視カメラの画像を用いる事で、3次元データを取得し、指をさした場所と指された物体を正確に認識することが可能となりました。
今後は、対話やジェスチャによりユーザから得られる情報を増やし、素早く検索結果を返せるようなインタフェースを構築していきます。また、システムのシーン解釈ミスをユーザとの対話により修正できるように改良する予定です。
3.1 特定人物の行動を常時見守りサポートする対話ロボットの開発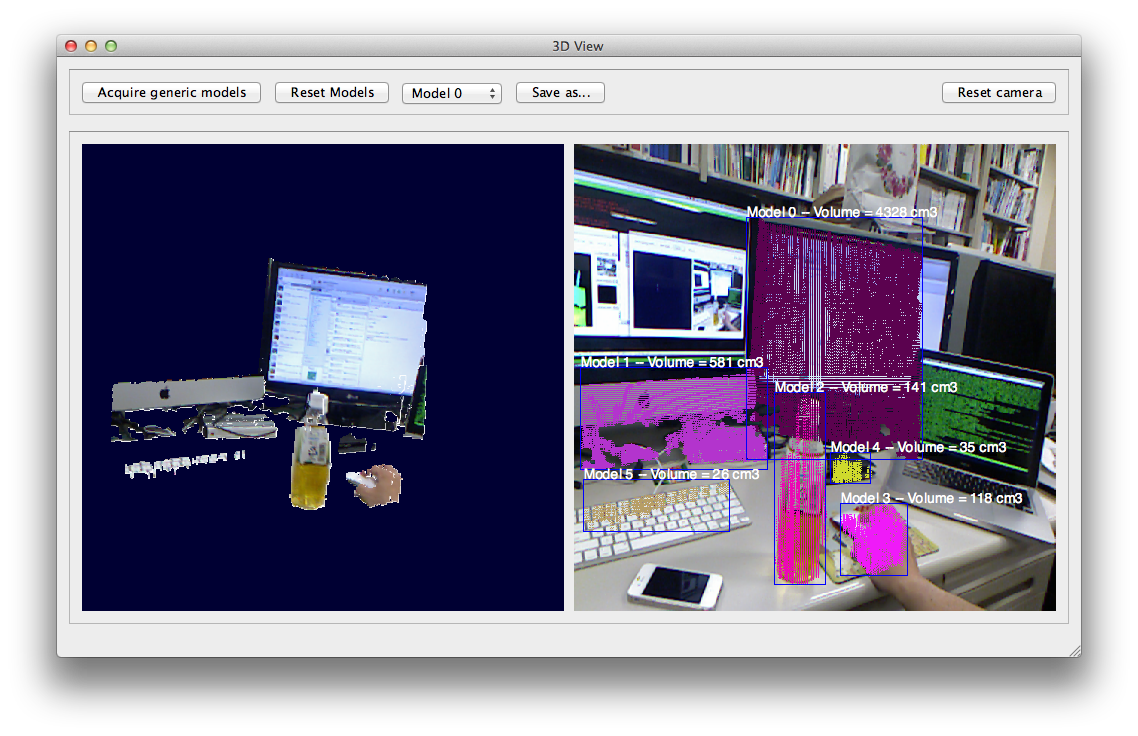
特定人物と物体との関わりを常時データベースに記録する事で、 ユーザが忘れた情報、知りたい情報の提供を行うシステムの開発を行なっています。 本システムは、Kinectから得られた物体と人間の関わりの情報を常時送信するクライント そして、ユーザと物体の関わりを記録するデータベースサーバ、 顔認識サーバで構成されています。
この研究を用いることで、監視システムによって得られた人物や顔情報をデータベースにアクセスすることでだれがその物体にイベントを起こしたのかが分かるようになり検索の機能の向上につながると考えている。
3.2 分散配置RGB-Dカメラのためのネットワーク指向型センサ/ディスプレイ基盤
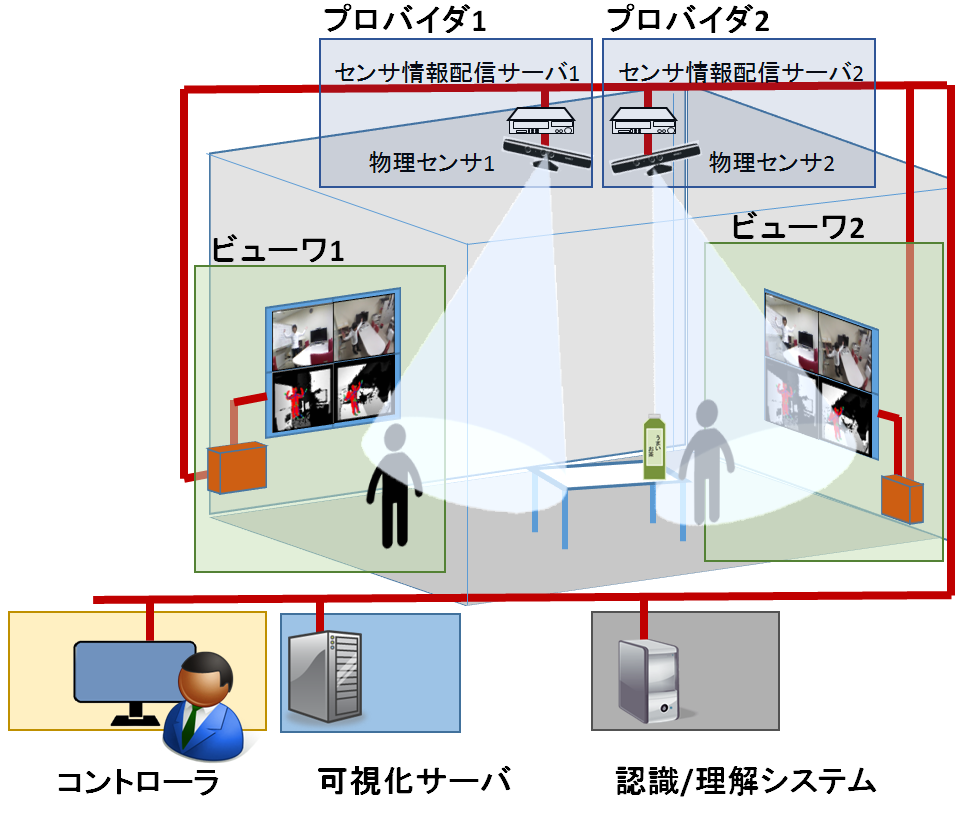
既存の監視システムでのイベント検知の精度を向上するためにRGB-Dセンサが導入されましたが、 RGB-Dセンサ自身にはネットワーク越しに自分自身が取得した色情報や距離情報を送る機能がありません。 そこでその役を担う配信サーバを構築し、センサ情報をネットワーク越しに配信できるようにすることで センサネットワークを広げることができるようになりました。
これに加え、センサ情報や監視システムの結果情報をどこからでも見ることができるようにその機能を担う ディスプレイをネットワーク上に分散させました。 このようなネットワーク指向型センサ/ディスプレイ基盤を構築することであらゆる地点のセンサ情報を取得し、 ネットワーク越しにどこからでも情報にアクセスすることができるようになります。

動画のようにコントローラ画面(左下)ではイベント検知部から可視化サーバを経由して送られてきた結果情報(リソース)のうちビューワに表示させたいものを選択・配置することができます。
ビューワ1の画面(左上), ビューワ2の画面(右上)ではコントローラによって選択・配置されたリソースがリアルタイムに反映・表示されています。 別々のマシンでビューワを表示させているところを外から撮った映像(右下)からもそのことが分かります。
課題点
1.従来のKinectデータの配信サーバーは画像データを
低解像度(480[pixel]×270[pixel])に制限して配信していましたが、
得られた画像は肉眼でみても手指の姿勢がはっきりと確認できないものでした。
KinectV2の最大スペックである高解像度(1920[pixel]×1080[pixel])で画像データの送受信を行うために、システムの書き換えと通信環境の整備を行いました。

低画像の場合

高画像の場合
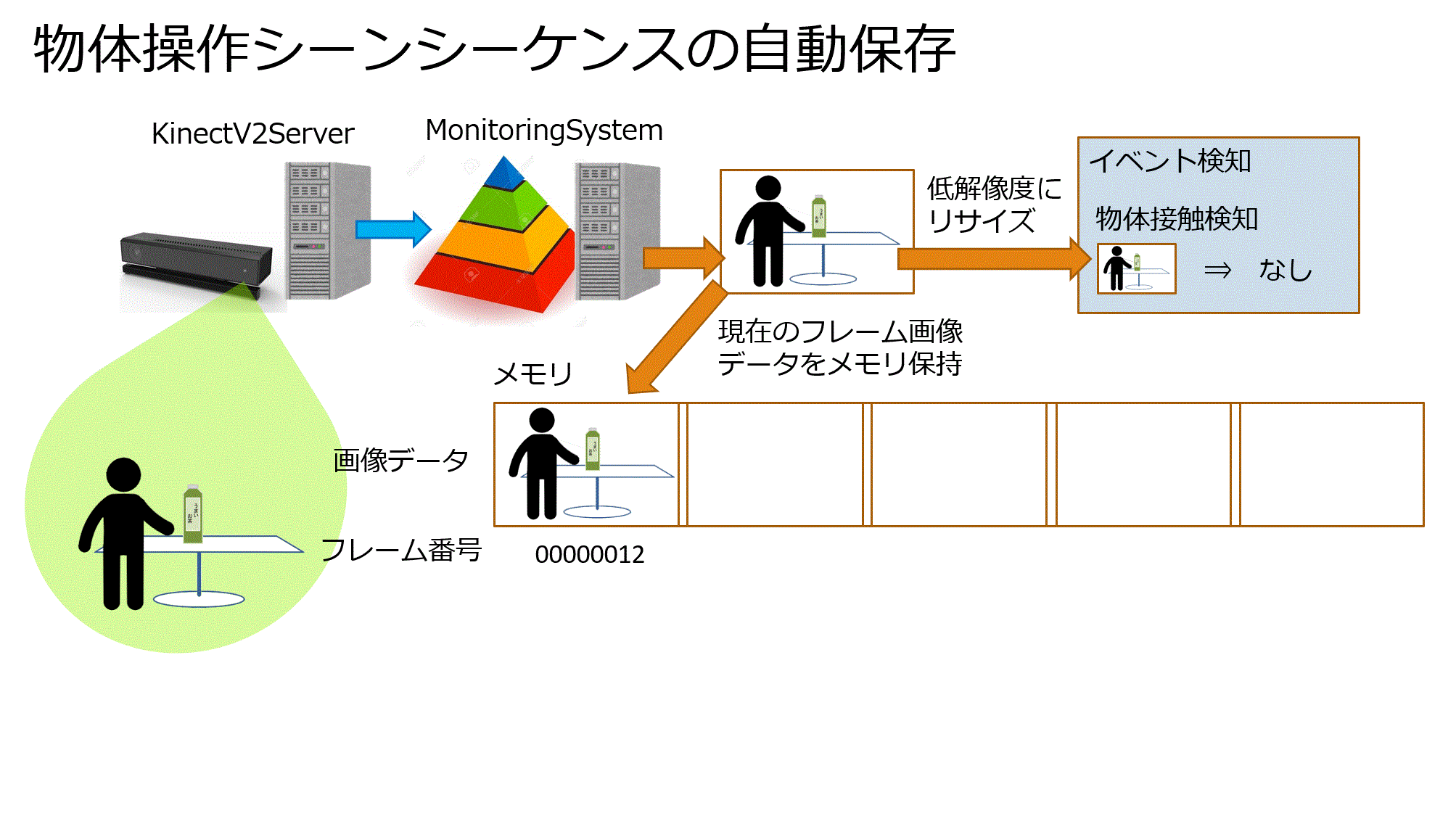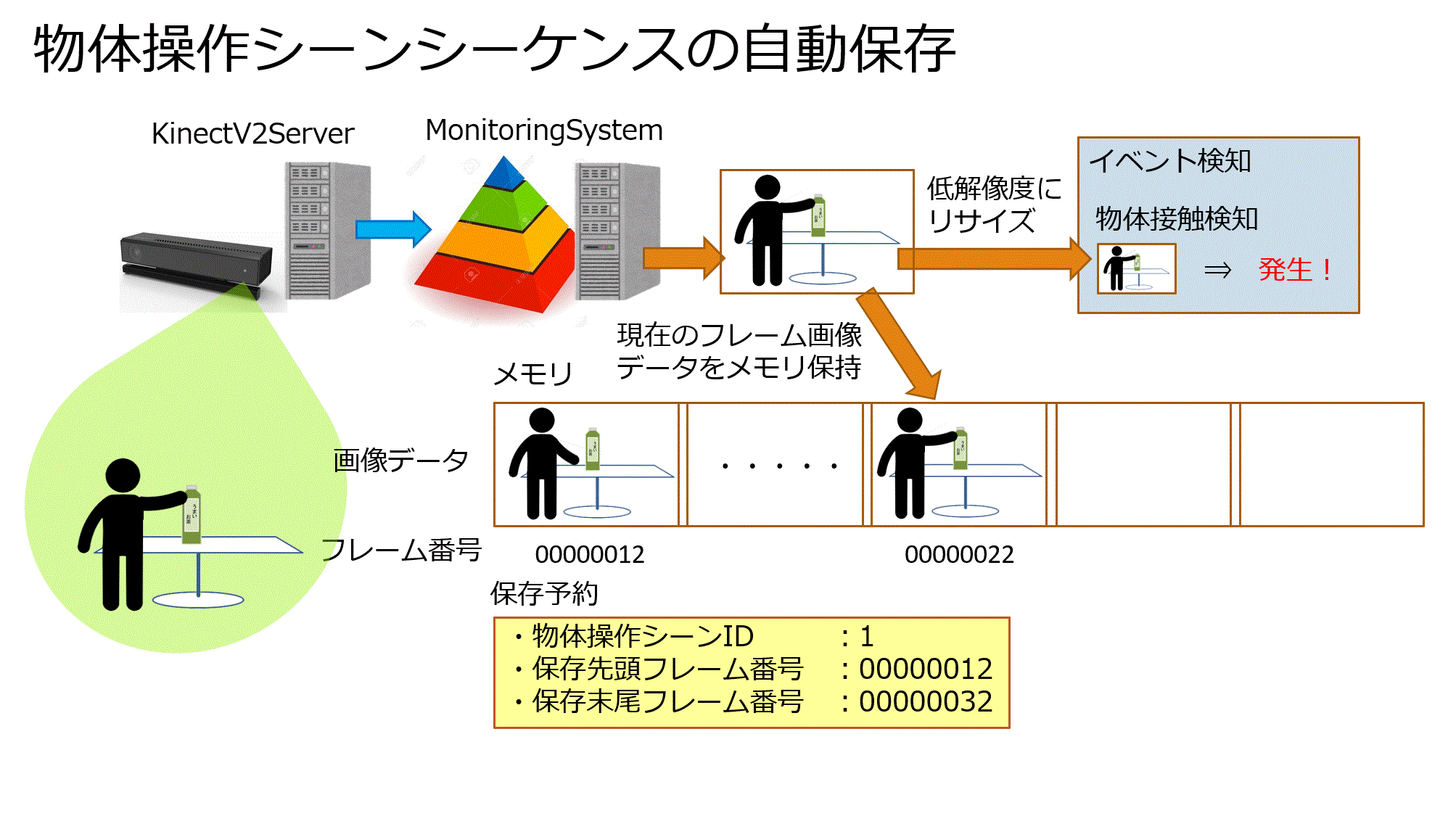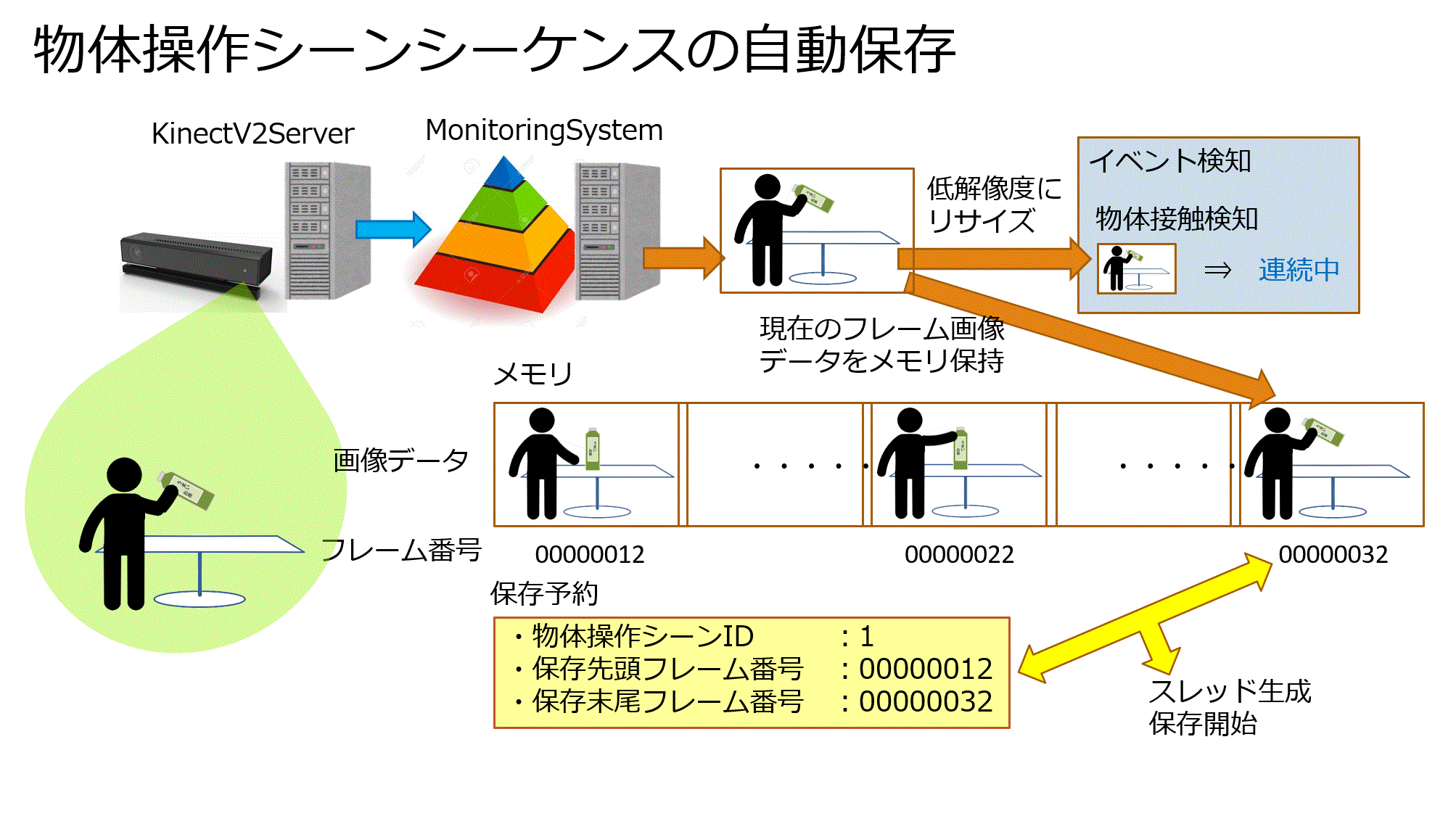
2.従来のイベント検知・解釈システムはイベントを検知した瞬間の画像1枚のみをデータベースに保存していました。
しかし物体操作シーンを学習させるにあたり
物体に接触する直前 ⇒ 物体を把持 ⇒ その後の物体操作
までの時系列を1つのシーンとして扱う必要があります。
ただし、高解像度画像を常に保存し続けるのは容量が大きくなり、長時間の実行に向かないので、必要な箇所だけ保存する必要がありました。

物体操作のシーケンス
OpenPoseによる骨格推定

高解像データ

低画像データ
時系列関節点群データの抽出


OpenPoseから得られた人物関節情報を元に、
物体位置を基準とした関節点群座標データを抽出しました
このデータを用いて学習を行います。
メンバ–
・卒業生
川本 祥悟 ( kawamoto [at] i.ci.ritsumei.ac.jp )
池上 貴之 ( ikegami [at] i.ci.ritsumei.ac.jp )
川北 真也 ( kawakita [at] i.ci.ritsumei.ac.jp )
寺西 研翔 ( teranishi [at] i.ci.ritsumei.ac.jp )
野川 哲史 ( nogawa [at] i.ci.ritsumei.ac.jp )
有本光希