目次
食品班

深層学習班

食品班
近年の労働人口の減少により,食品産業界ではロボットによる作業の自動化が求められています。しかし、工業製品と異なり食品は形状がそれぞれ異なるため、人が設計した一連のアルゴリズムで操作を行うことは困難とされています。
そのような操作を自動化するには、まず画像から必要な情報を取り出し、その情報を元にロボットを動かす必要があります。本研究では深層学習を用いて画像から必要な情報を取得することを目標としています。
これに際して、株式会社ニップンさん、株式会社味の素冷凍食品さん、本学理工学部のソフトロボティクス研究室(平井研)と共同で研究を行い、把持作業の自動化に取り組んでいます。
1.粒状食材の定量把持
この研究は株式会社ニップンさんと本学理工学部ソフトロボティクス研究室(平井研)との共同研究です。
1-a 重量推定深層学習モデル
トッピングとして使われるネギやコーン、グリーンピースなどの粒状食材が積まれた容器から指定された量を掬い取るために、どの場所に、どの程度のロボット動作量で動作させればよいかを推定しロボットを自動で制御します。
粒状食材の定量トッピング作業を自動化するために、本研究では深層学習モデルを用いて、表層の状況を表すRGB-D画像とロボットの動作量を入力に把持重量を推定します。把持重量が推定できれば、推定した把持重量からロボットの動作量を逆算することができるようになります。

しかし入力となるのは表層の状況を表すRGB-D画像であり、食材の内部の状況や粒状食材同士が起こす偶発性などによって、入力画像以外の要素が把持重量に影響してしまいます。
これらの影響は食材状況によって小さい箇所と大きい箇所があるはずです。そこで把持重量の代わりに把持重量の確率分布を推定します。実際に掬いに行く場所は、目標把持重量と推定把持重量期待値が等しく、推定把持重量の分散(ばらつき度合い)が小さい状況を選択すればよいことになります。
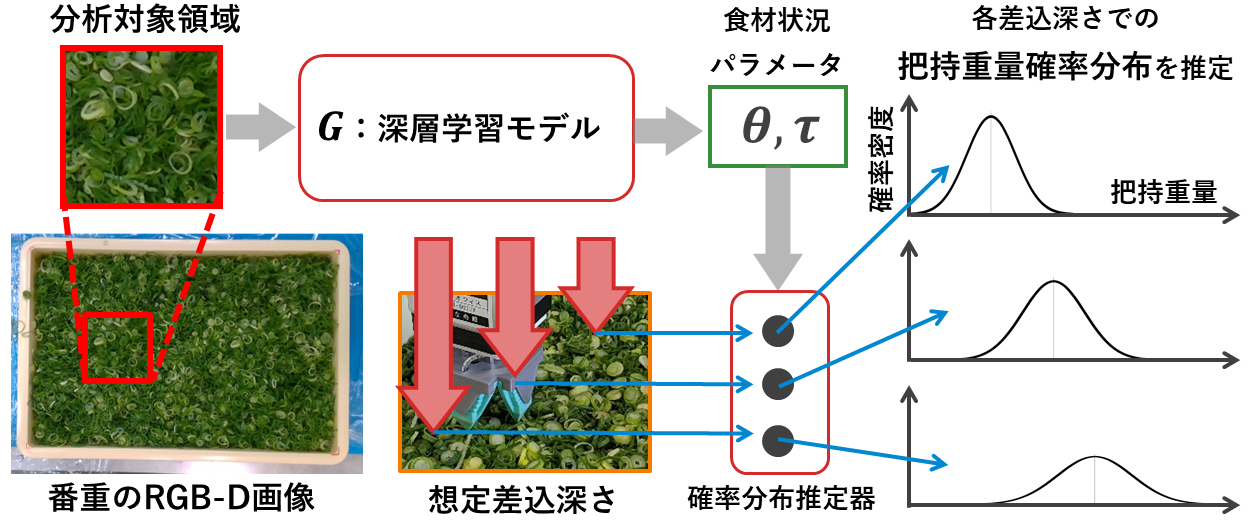
株式会社ニップンさんから頂いたデータで深層学習を行い、深層モデルを作成しました。このモデルが番重全体のRGB-D画像に対して、把持重量のばらつき度合いをどのように推定しているか確認しました。以下の図は20[g]の把持条件のときに、ある番重全体の画像から推定した把持重量の標準偏差を可視化した図です。
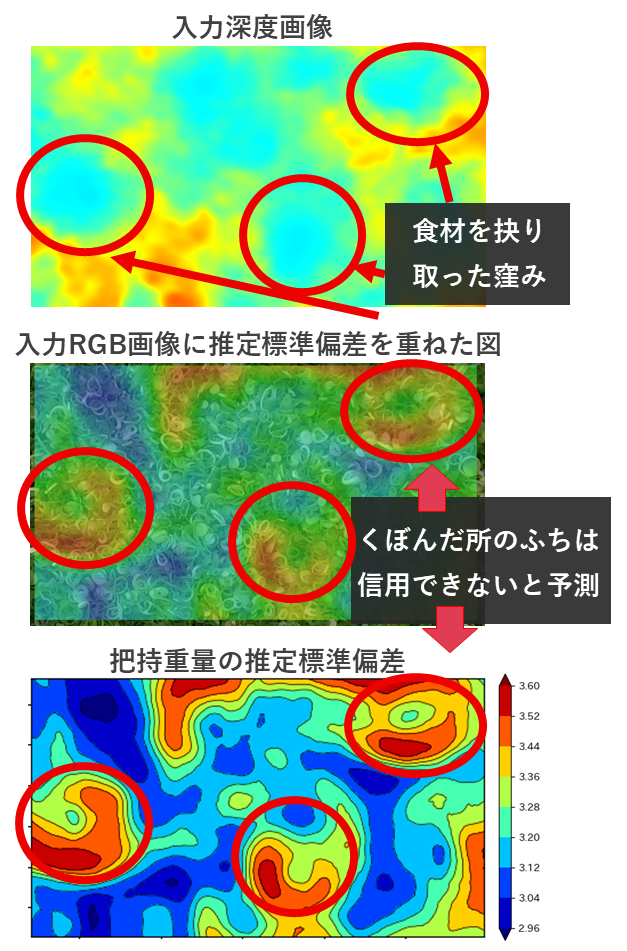
この番重全体画像は既にいくらか把持実験を行っており、食材をえぐり取った複数のくぼみが存在します。これに対して把持重量の推定標準偏差は入力深度画像と関連があることがうかがえます。
くぼんだ箇所のふちにあたる傾斜が大きい場所での把持重量の推定標準偏差は大きく出力され、その場所での把持重量は信用できないと推定しています。この推定は、私たちがネギを上から把持しようとしたときの直感に近い標準偏差の推定が行われていることを示しています。
今後の展望は、ドメイン適応の技術を用いてネギの情報を他の粒状食材にも適用することです。すると、同じレーンで多くの種類に対して決まった重量を把持するロボットハンドを作成できるかもしれません。
深層学習モデルで確率分布を推定することは行われてきたものの、これをロボット制御に適応した例は少ないです。
1-b トレンド推定によるコンセプトシフト適応
先ほどの提案モデルでは,訓練・検証データに適合するものの,別日に把持実験を行うと推定が系統的にシフトすることが課題です.
シフトの原因は既存手法そのものではなく課題のデータ特性によるものでしょう.食材は対象の時間が経過したり,気温や湿度などの環境の変化によって,水分量や密度が変わってしまいます.こうなると,RGBDカメラから得る、表面のビジョンだけで食材重量の変動をとらえることができません.
このように,説明変数は変わらないのに目的変数がシフトすることを「コンセプトシフト」といいます.コンセプトシフトは入出力関係そのものが変わるので,定期的にテストデータで転移学習する必要があります.
また本課題は、過去の把持データに似た状況が再び現れることがあります.さらに全国にある工場でそれぞれ異なる食材をトッピングしなければならず,すべての工場の環境を完全に一致させることはできません.個別のモデルを用意するのはコストがかかりすぎます.そこで,コンセプトシフトを抑制し多様な環境を単一モデルで適応するトレンド推定を提案します.
本研究では説明変数に陽に現れない、時間とともに変化する隠れ環境状態を「トレンド」と定義します.「過去に類似した状況が再現される」ということは、データの背後に隠れた環境状態が存在することを示唆しています。シフトが再現するのであれば、シフトを例外として扱うのではなく、データが持っている特性だとして,モデルに組み込むことができます.
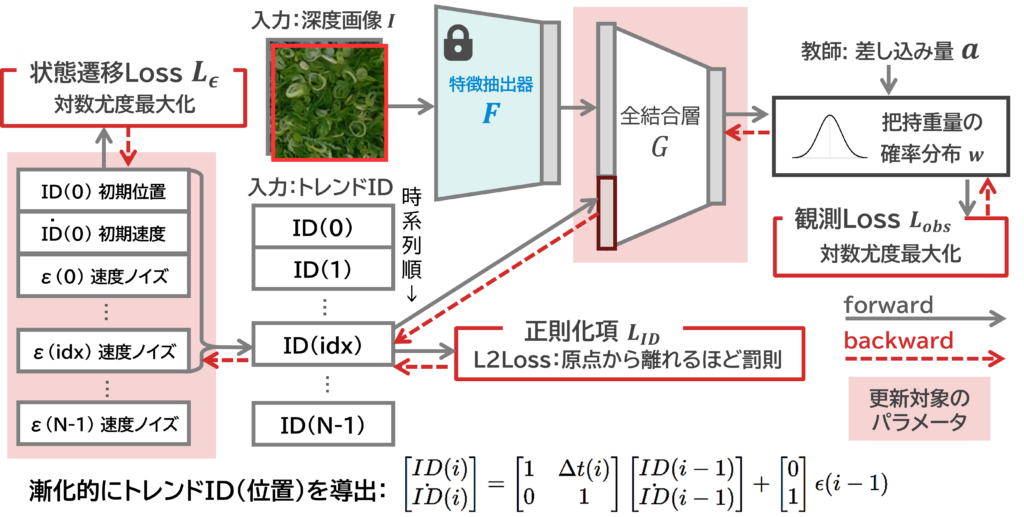
隠れ環境ベクトル「トレンド」をモデルに明示的に埋め込むことで、単一の統合モデルで様々な環境・食材・時系列に適応することができます.多拠点で利用することを念頭に置いたモデルであり,今後は社会実装に向けた開発を進めていきます.
1-c 多拠点間統合学習を見据えた食品の定量把持システム
多拠点間統合学習を見据えて食品の定量把持を行うためのROS2システムを実装しています。多拠点間統合学習とは、異なる物理的な場所に配置された複数のロボットが同じシステムや画像認識モデルで動作し、その収集されたデータを中央の場所に統合して学習を行う手法です。すべての工場の環境(ロボットアーム、カメラ位置や食品の状態など)を完全に一致させることは不可能であることから、全国各地の工場がネットワークで接続され、各工場での学習用データを中央サーバーで管理し、学習するような多拠点間統合学習が可能なシステム開発を目指しています。
システムの構造はこのようになっています。ROS2を使うことでメッセージ型が同じノードは交換することができ、拡張性のある構成となっています。
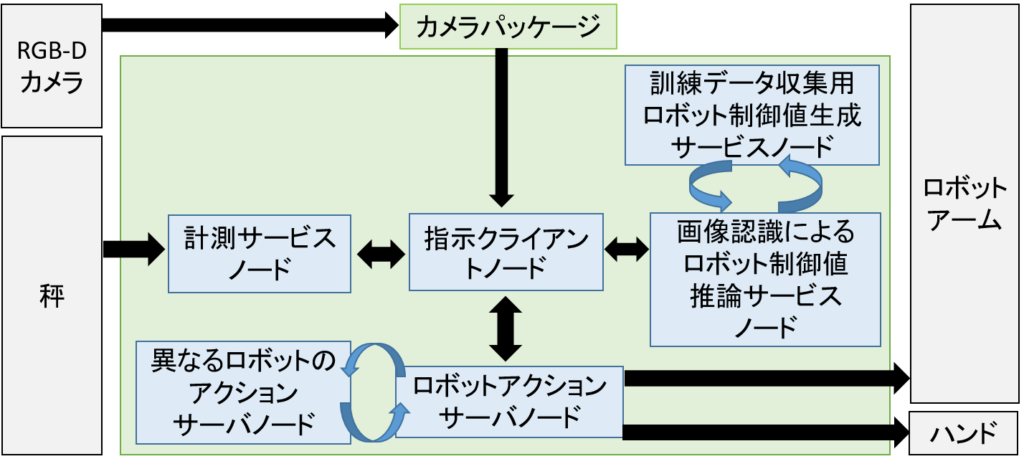
このような環境で1-aの深層学習モデルを使用して実験を行っています。
また、ロボットアームを変更しての適用も行いました。国際ロボット展2023で展示を行いました。4日間にわたる運用も達成し、このシステムでの長期間動作に対する可能性も示されました。
2.パッキング作業自動化のための画像処理
この研究は株式会社味の素冷凍食品さんとの共同研究です。
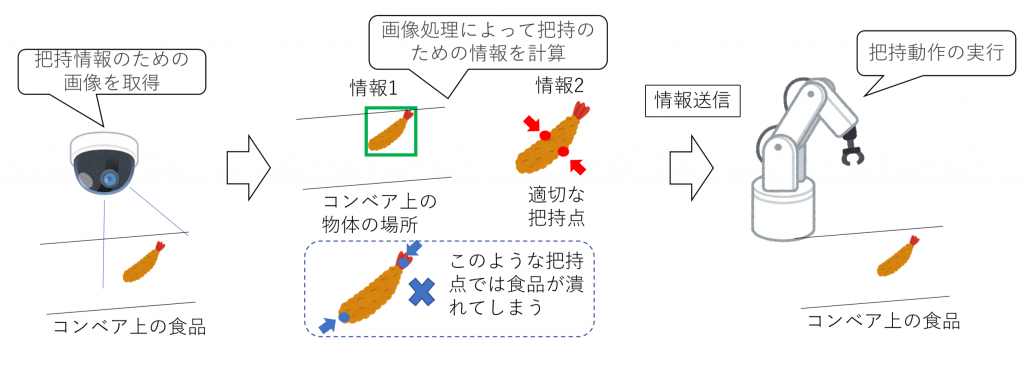
ロボットハンドによる食品把持のために、コンベア上の食品の位置と各食品の把持するべき点を画像から推定します。このためには、以下の2つの情報が必要となります。
- 対象となる食品が画像上の何処に写っているかという情報
- その食品を把持するのに適した点は何処かという情報
この2つの情報を食品が写った画像から推定をする試みを行っています。
3.良品不良品判別作業自動化についての画像認識
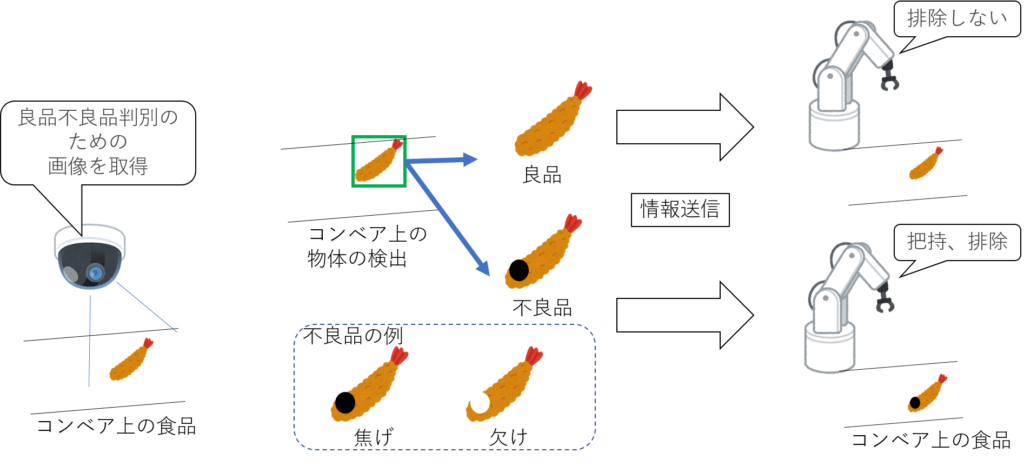
「2.パッキング作業自動化のための画像処理」の研究内容を応用して、コンベア上に流れる食品が良品か不良品かを深層学習を用いて判別する試みを行っています。
仮に食品が不良品であった場合はハンドで把持動作を実行し、コンベア上から排除するようにしています。
4.食材盛り付け画像と生成手順の想起
弁当食材の画像と少数の盛り付け例データセットを用いて、弁当や皿上に食材を盛り付ける配置と盛り付け手順を想起する手法について研究します。
各食材の置いた手順及び位置をロボットに指示することが重要です。
そのため、お弁当の画像内のオブジェクトおよび関係を学習し想起できる方法について研究を進めています。

深層学習班
近年、深層学習の著しい進歩によって、ネットワークの性能が大幅に上昇し、以前想像も付かない場面で応用できるようになりました。
特に、Deep Convolutional Network、Attention Mechanismを代表としたネットワーク構造の発展に伴って、深層学習が画像認識・画像生成で活用することが段々多くなりつつあります。
このように発展された深層学習の能力を実際の応用に発揮することを目的として、本研究室は深層学習班を設けました。
5.キャラクターデザイン支援
GANを用いたキャラクター画像の姿勢変換
キャラクターの画像と変換先の姿勢画像(PoseMask)を入力
↓
キャラクターが変換先の姿勢をしている画像を出力
目標として、キャラクターデザインをする時、ラフスケッチ一枚でキャラクターの様々な姿勢をする姿を確認できるようにしたい

6.Compositional GANに基づく眼鏡を装着した顔画像の生成
既存研究に基づいて、横を向いた顔にも対象として、眼鏡のサイズが合わない、位置をずらす問題を改善を行います。
そして、もとのデータセットの中で、主には前向きの顔画像なので、横顔に適用できません。
それで、データセットの顔画像に対する前処理を行って、顔の68点のランドマークを得られます。
そして、各画像のランドマークは画像情報と繋がって、眼鏡の平行回転パラメータを計算します。

7.時空間特徴抽出に基づくの手話翻訳
・世界のさまざまな国の言語は基本的に相互に翻訳できる。これを実現できる翻訳ソフトウェアはたくさんある。

Google翻訳のように人工ではない方法で手話を翻訳することはできない
・手話は、手の動き、口の形、表情を組み合わせた言語。国によって手話の表現にも違いがある。同じ国でも手話に違いがあるかもしれない。

手話の翻訳を困難にする
手話を可能な限り正確に健常者が使用する言語に翻訳することを目的とする

8.オノマトペと画像のマルチモーダル分散表現の構築
人間はオノマトペ単語から想起される物体の質感や情報は曖昧に理解しながら用いており、正確な質感イメージの共有は困難です。
そこでオノマトペの特徴を表した分散表現を獲得することができれば物体の質感特徴から最適な言語表現を生成してユーザに正確な質感イメージを提供することが可能になると考えられます。
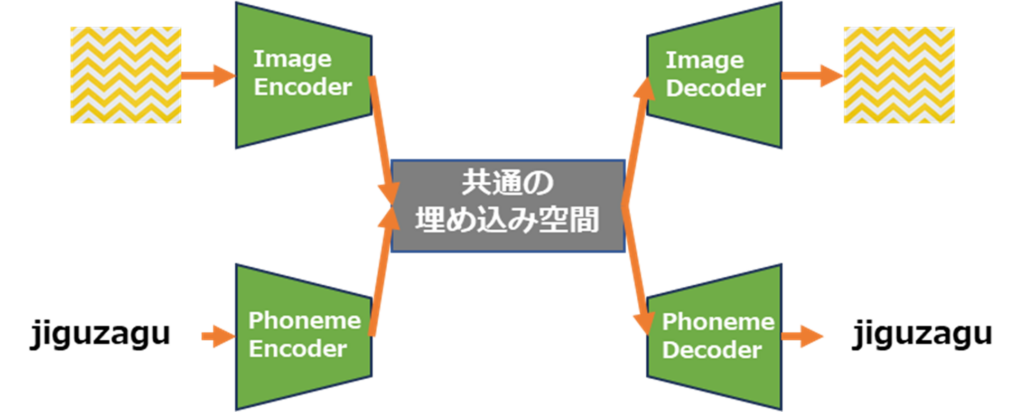
本研究では入力画像のテクスチャが復元されるように画像を生成する際に用いられる潜在変数とオノマトペから得られるオートエンコーダの潜在変数を近づけるように学習させ、共通の埋め込み空間を構築します。これによりあるオノマトペからそれに適したテクスチャ画像の生成と、あるテクスチャ画像からそれに適したオノマトペの生成を実現し、オノマトペと画像のマルチモーダル空間の構築を目指しています。
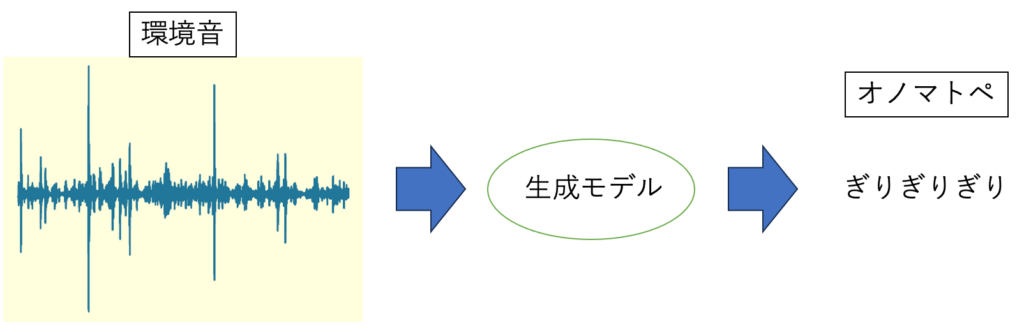
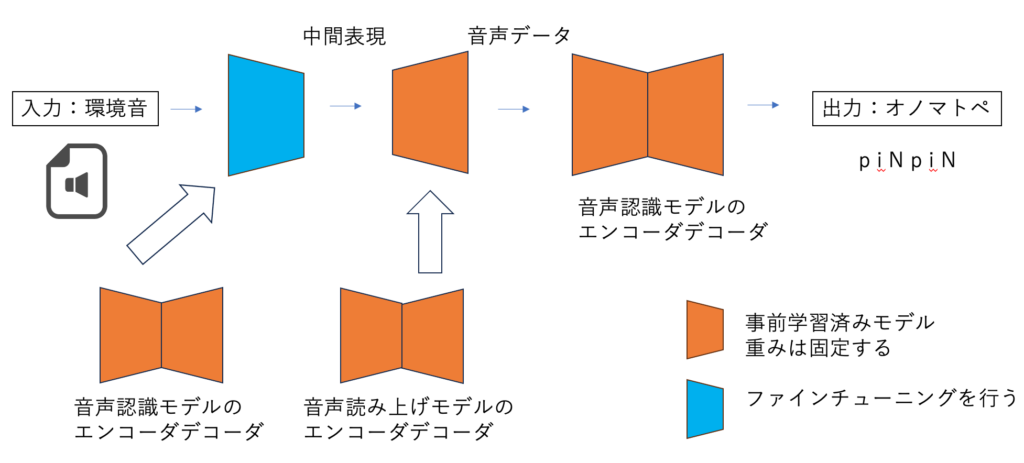
9.深層モデルを用いた環境音からのオノマトペ生成
近年、GPT-4を始めとした多くの生成モデルが存在しますが、オノマトペのような言葉とパターンの中間的な表現を用いたものは数が少ないです。
オノマトペと音声に着目した先行研究として、オノマトペから環境音を生成するモデルが存在します。
本研究では、先行研究とは対照的に、環境音からのオノマトペ生成を行う深層モデルの作成を行っています。
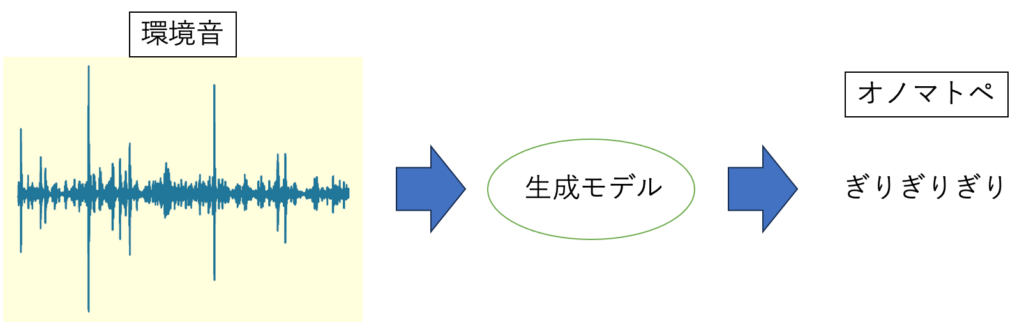
モデルの作成には学習済みの音声認識モデルと音声読み上げモデルを用いています。CTC損失関数を用いて、モデルから出力されるオノマトペを答えのオノマトペに近づけるように学習することで環境音からオノマトペの音素を得られるかを研究しています。
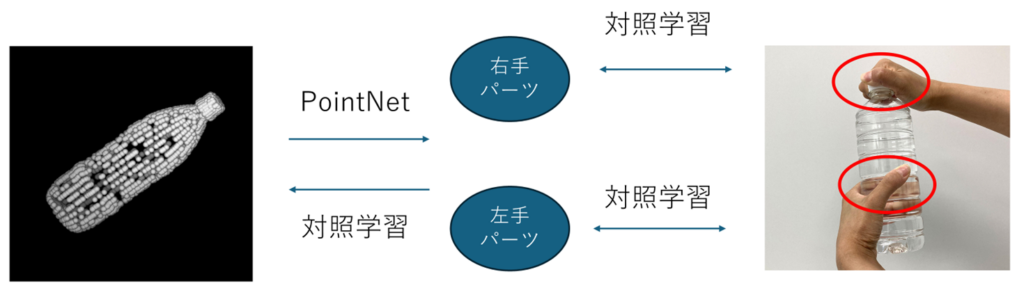
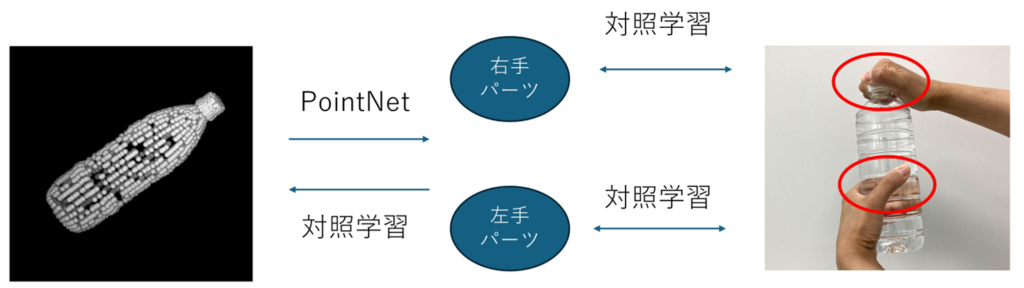
10. 接触部位形状を介した物体形状と両手把持ジェスチャの相互想起
ロボットハンドの把持姿勢の決定には、物体形状と対象物体に応じた把持姿勢の情報が必要である。物体形状を学習する多くの研究では、物体の全体形状で学習しているため物体の全体形状が似る物体にのみ有効である。しかしながら、やかんやバスケットのような物体の全体形状が異なる物体同士でも、両手把持姿勢が似る物体がある。そこで、把持姿勢は物体の全体形状ではなく、接触部位形状と対応付けられていると考えた。
本研究では、以下のようなモデルの構築を目指す。全体形状と接触部位形状がPointNetと対照学習で相互に行き来する形になっている。全体形状から接触部位形状を取得するときに対象学習を用いると、全体形状に含まれない形状が取得されうるからである。また、両手把持ジェスチャから物体の全体形状の想起は、接触部位形状は把持姿勢から取得される。その際、必ずしも両パーツ形状が同じIDのものが得られるとは限らないためこのような構想を考えた。また、各パーツ形状を入力にしてそれを把持するような手形状の生成も目指します。
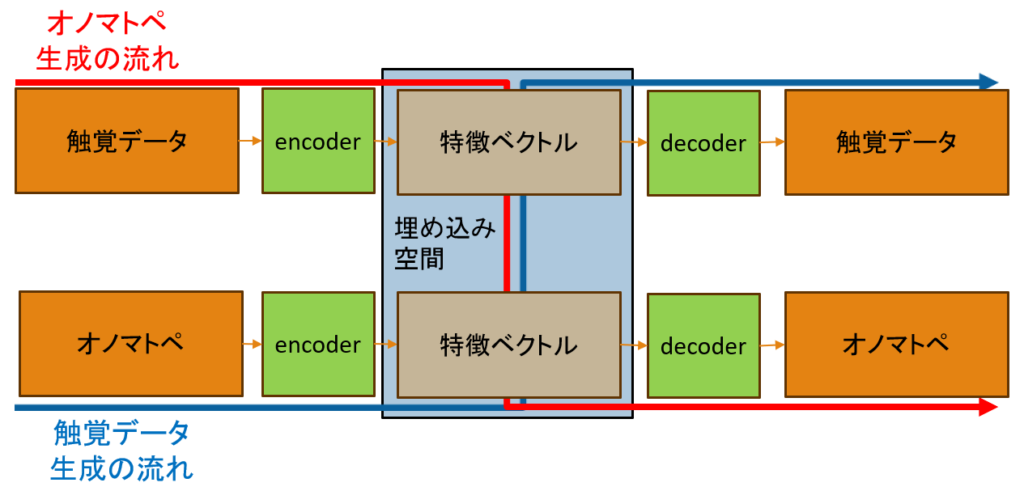
11.深層学習による触覚データとオノマトペのマルチモーダル変換
近年、マルチモーダル変換の進歩により、異なる種類のデータを組み合わせて新たな視点から考察する技術が注目を集めています。例えば、テキストと画像を用いて映像を生成したり、テキストと音声データを活用して歌を作り出すプログラムなど、さまざまな応用例が登場してきました。こうした背景には、ディープラーニングなどの人工知能技術が高度化し、複数モダリティを統合的に扱えるようになったことが大きく寄与しています。
本研究では、そのようなマルチモーダル変換の一環として、触覚データとテキスト、その中でもオノマトペを総合的に扱うモデルを提案します。具体的には、触覚データとオノマトペを固定長の特徴ベクトルへ圧縮し、相互に変換することで、より多彩で奥行きのある情報表現を目指す基盤を構築することを目的としています。